
[ 1 ]
Speaker-Adaptive TTS
Meet the people working on it!
Research Overview
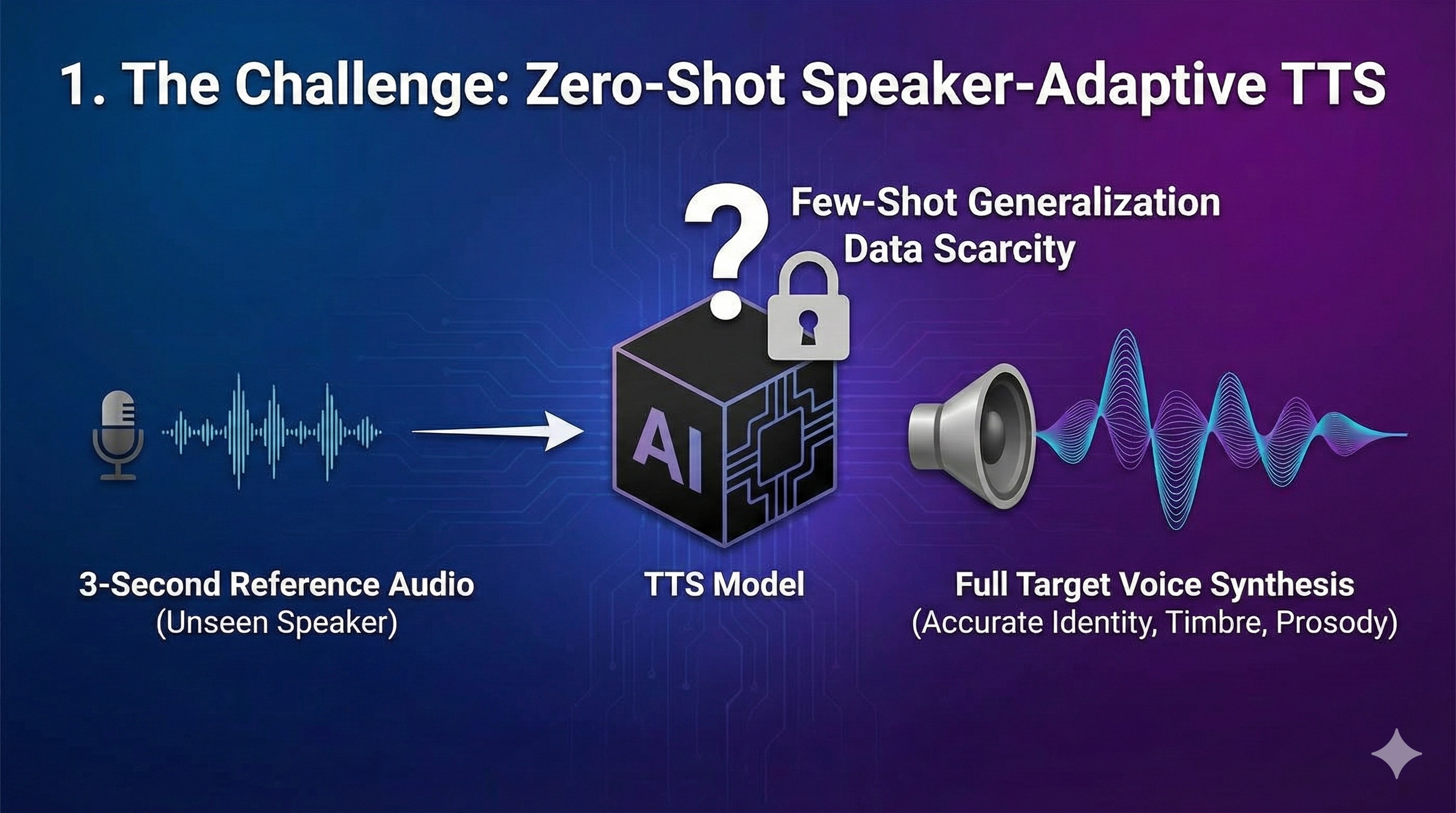
Speaker-Adaptive Text-to-Speech (TTS) aims to synthesize natural-sounding speech that accurately mimics the identity, timbre, and prosody of a specific target speaker, often requiring only a few seconds of reference audio (Zero-Shot scenario).
My research expands the frontiers of this field by addressing critical challenges in generalization, cross-lingual adaptation, and data scarcity.
Project Slides
Related Papers
[ 2 ]
USAT: A Universal Speaker-Adaptive Text-to-Speech Approach
IEEE/ACM Transactions on Audio, Speech, and Language Processing (TASLP), Vol. 32
(2024)
[ 3 ]
[ 4 ]
Generalizable Zero-Shot Speaker-Adaptive Speech Synthesis with Disentangled Representations
Interspeech (Oral)
(2023)
[ 5 ]
AutoLV: Automatic lecture video generator
IEEE International Conference on Image Processing (ICIP)
(2022)