Action Planing
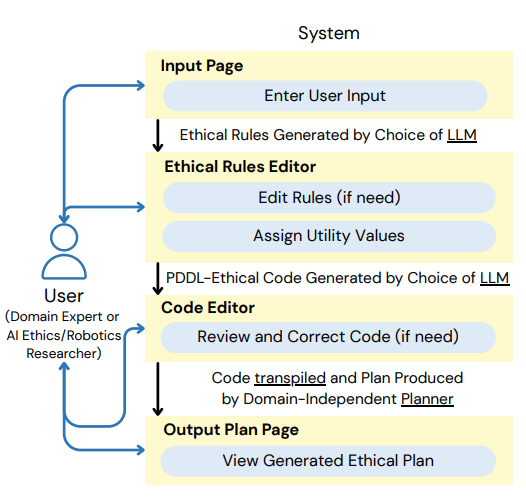
Principles2Plan: LLM-Guided System for Operationalising Ethical Principles into Plans | Link in here
Ethical awareness is critical for robots operating in human environments, yet existing automated planning tools provide little support. Manually specifying ethical rules is labour-intensive and highly context-specific. We present Principles2Plan, an interactive research prototype demonstrating how a human and a Large Language Model (LLM) can collaborate to produce context-sensitive ethical rules and guide automated planning. A domain expert provides the planning domain, problem details, and relevant high-level principles such as beneficence and privacy. The system generates operationalisable ethical rules consistent with these principles, which the user can review, prioritise, and supply to a planner to produce ethically-informed plans. To our knowledge, no prior system supports users in generating principle-grounded rules for classical planning contexts. Principles2Plan showcases the potential of human-LLM collaboration for making ethical automated planning more practical and feasible.
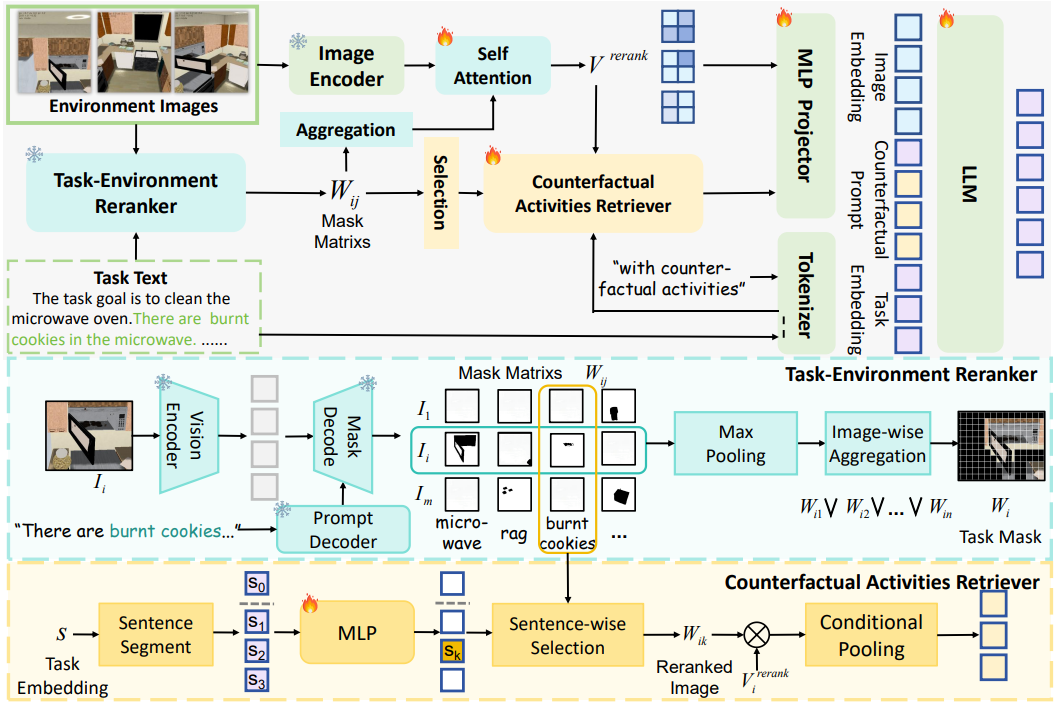
LLaPa: A Vision-Language Model Framework for Counterfactual-Aware Procedural Planning | Link in here
While large language models (LLMs) have advanced procedural planning for embodied AI systems through strong reasoning abilities, the integration of multimodal inputs and counterfactual reasoning remains underexplored. To tackle these challenges, we introduce LLaPa, a vision-language model framework designed for multimodal procedural planning. LLaPa generates executable action sequences from textual task descriptions and visual environmental images using vision-language models (VLMs). Furthermore, we enhance LLaPa with two auxiliary modules to improve procedural planning. The first module, the Task-Environment Reranker (TER), leverages task-oriented segmentation to create a task-sensitive feature space, aligning textual descriptions with visual environments and emphasizing critical regions for procedural execution. The second module, the Counterfactual Activities Retriever (CAR), identifies and emphasizes potential counterfactual conditions, enhancing the model's reasoning capability in counterfactual scenarios.