Action Recognition
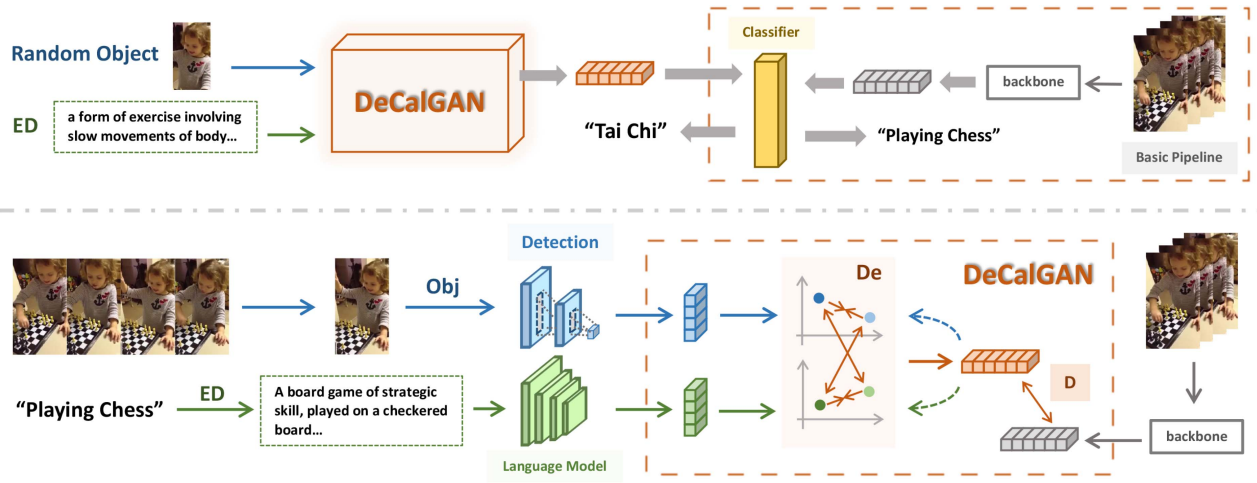
Deconfounding Causal Inference for Zero-Shot Action Recognition | Link in here
Zero-shot action recognition (ZSAR) aims to recognize unseen action categories in the test set without corresponding training examples. Most existing zero-shot methods follow the feature generation framework to transfer knowledge from seen action categories to model the feature distribution of unseen categories. However, due to the complexity and diversity of actions, it remains challenging to generate unseen feature distribution, especially for the cross-dataset scenario when there is a potentially larger domain shift. This article proposes a Deconfounding Ca USAl GAN (DeCalGAN) for generating unseen action video features with the following technical contributions: 1) Our model unifies compositional ZSAR with traditional visual-semantic models to incorporate local object information with global semantic information for feature generation. 2) A GAN-based architecture is proposed for causal inference and unseen distribution discovery. 3) A deconfounding module is proposed to refine representations of local objects and global semantic information confounder in the training data.
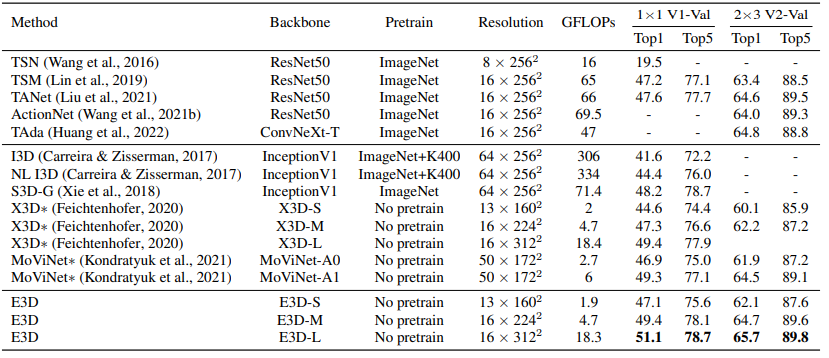
Maximizing Spatio-Temporal Entropy of Deep 3D CNNs for Efficient Video Recognition | Link in here
3D convolution neural networks (CNNs) have been the prevailing option for video recognition. To capture the temporal information, 3D convolutions are computed along the sequences, leading to cubically growing and expensive computations. To reduce the computational cost, previous methods resort to manually designed 3D/2D CNN structures with approximations or automatic search, which sacrifice the modeling ability or make training time-consuming. In this work, we propose to automatically design efficient 3D CNN architectures via a novel training-free neural architecture search approach tailored for 3D CNNs considering the model complexity. To measure the expressiveness of 3D CNNs efficiently, we formulate a 3D CNN as an information system and derive an analytic entropy score, based on the Maximum Entropy Principle. Specifically, we propose a spatio-temporal entropy score (STEntr-Score) with a refinement factor to handle the discrepancy of visual information in spatial and temporal dimensions, through dynamically leveraging the correlation between the feature map size and kernel size depth-wisely.