Anomaly Detection
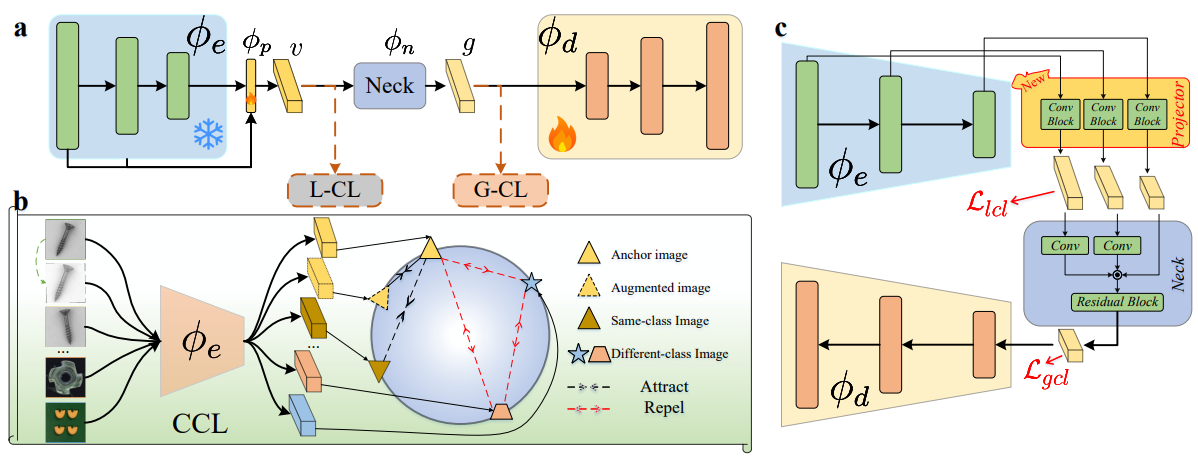
Salvaging the Overlooked: Leveraging Class-Aware Contrastive Learning for Multi-Class Anomaly Detection | Link in here
For anomaly detection (AD), early approaches often train separate models for individual classes, yielding high performance but posing challenges in scalability and resource management. Recent efforts have shifted toward training a single model capable of handling multiple classes. However, directly extending early AD methods to multi-class settings often results in degraded performance. In this paper, we investigate this performance degradation observed in reconstruction-based methods, identifying the key issue: inter-class confusion. This confusion emerges when a model trained in multi-class scenarios incorrectly reconstructs samples from one class as those of another, thereby exacerbating reconstruction errors. To this end, we propose a simple yet effective modification, called class-aware contrastive learning (CCL). By explicitly leveraging raw object category information (g carpet or wood) as supervised signals, we introduce local CL to refine multiscale dense features, and global CL to obtain more compact feature representations of normal patterns, thereby effectively adapting the models to multi-class settings.
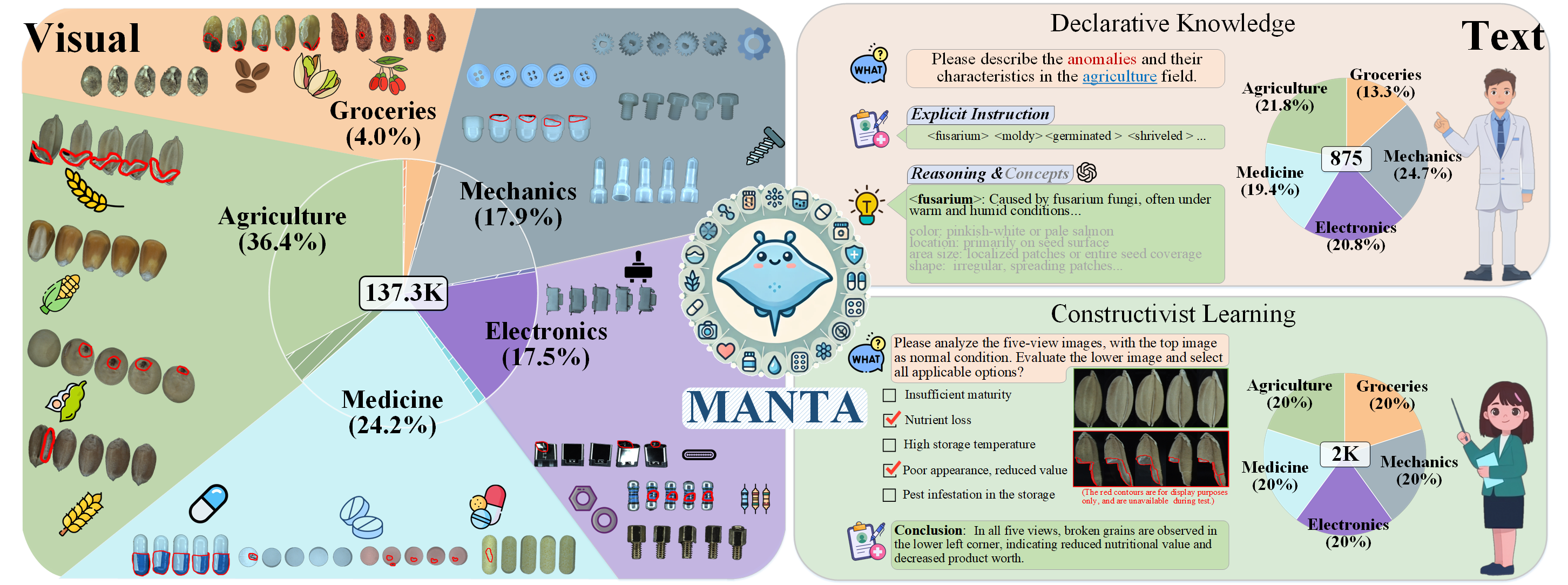
MANTA: A Large-Scale Multi-View and Visual-Text Anomaly Detection Dataset for Tiny Objects | Link in here
We present MANTA, a visual-text anomaly detection dataset for tiny objects. The visual component comprises over 137.3K images across 38 object categories spanning five typical domains, of which 8.6K images are labeled as anomalous with pixel-level annotations. Each image is captured from five distinct viewpoints to ensure comprehensive object coverage. The text component consists of two subsets: Declarative Knowledge, including 875 words that describe common anomalies across various domains and specific categories, with detailed explanations for < what, why, how>, including causes and visual characteristics; and Constructivist Learning, providing 2K multiple-choice questions with varying levels of difficulty, each paired with images and corresponded answer explanations. We also propose a baseline for visual-text tasks and conduct extensive benchmarking experiments to evaluate advanced methods across different settings, highlighting the challenges and efficacy of our dataset.