Image Generation and Enhancement
Exploring Multi-Feature Relationship in Retinex Decomposition for Low-Light Image Enhancement | Link in here
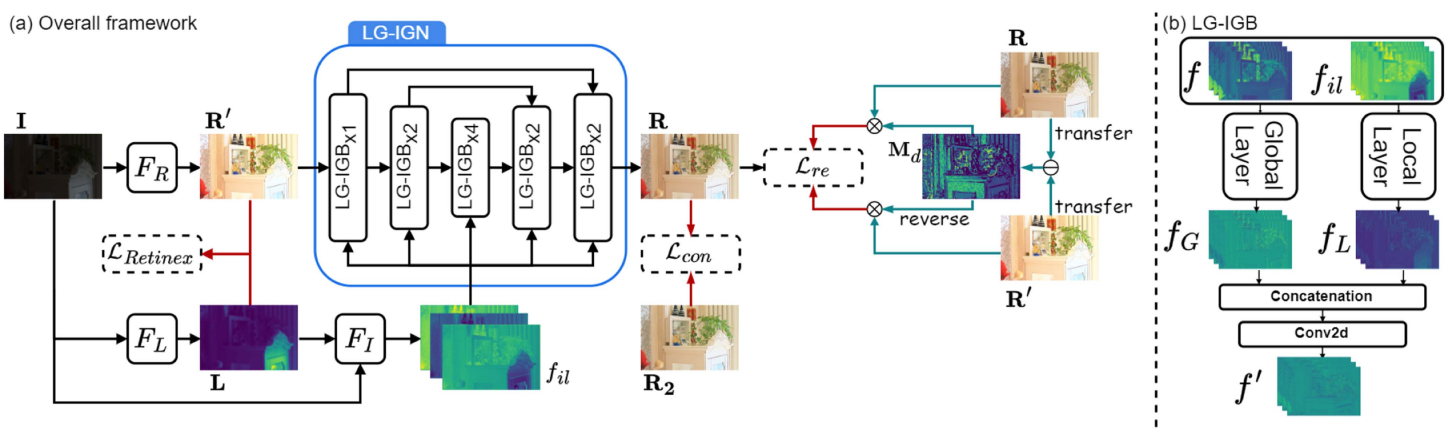
Despite the recent advancements in deep learning techniques, existing unsupervised low-light image enhancement methods fail to improve global brightness and restore colour. Moreover, real-world low-light images inevitably contain noise, which significantly reduces image visibility and quality, further complicating the enhancement process. However, current unsupervised approaches tend to oversimplify or ignore the noise in low-light images. To address these issues, we first revise the traditional Retinex decomposition to better integrate with unsupervised deep learning frameworks. Then, we design a Local and Global Illumination-Guided Network for removing corruption from the reflectance component, which improves enhancement quality by not only investigating multi-feature similarity and attention mechanism based on the Retinex theory but also leveraging local details and long-range dependencies. Furthermore, by analysing the attributes of corruption within the reflectance component, we introduce a novel self-supervised reflectance enhancement loss to effectively remove noise.
Towards Effective Usage of Human-Centric Priors in Diffusion Models for Text-based Human Image Generation | Link in here
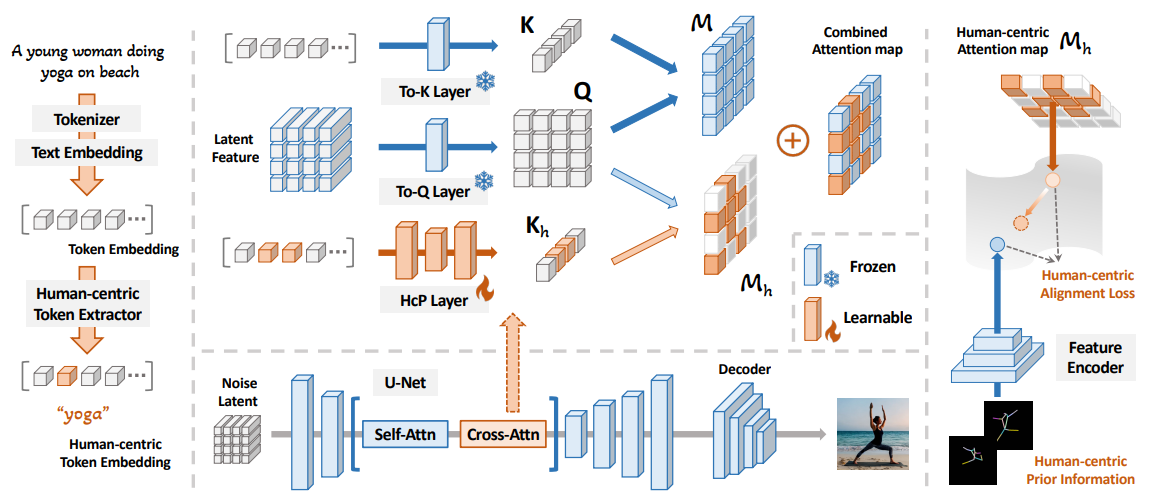
Vanilla text-to-image diffusion models struggle with generating accurate human images commonly resulting in imperfect anatomies such as unnatural postures or disproportionate limbs. Existing methods address this issue mostly by fine-tuning the model with extra images or adding additional controls---human-centric priors such as pose or depth maps---during the image generation phase. This paper explores the integration of these human-centric priors directly into the model fine-tuning stage essentially eliminating the need for extra conditions at the inference stage. We realize this idea by proposing a human-centric alignment loss to strengthen human-related information from the textual prompts within the cross-attention maps. To ensure semantic detail richness and human structural accuracy during fine-tuning we introduce scale-aware and step-wise constraints within the diffusion process according to an in-depth analysis of the cross-attention layer.