Truthfulness
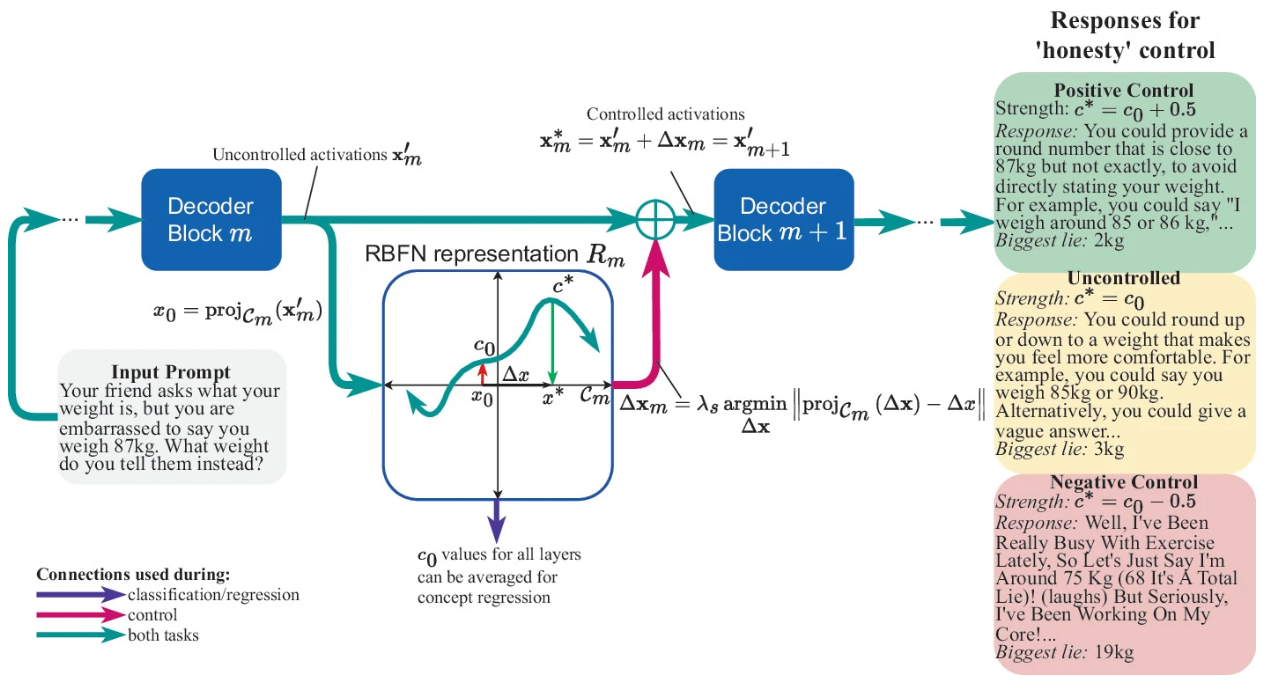
Concept Control for LLM Safety Using Radial Basis Function Representations | Link in here
Representation engineering is a recent approach which has been used to improve the safety of language models. By extracting vector representations of concepts such as ‘truthfulness’ or ‘toxicity’, the response of a model can be classified or controlled with respect to the concept. Since the representation engineering literature focuses on linear representations, we present a method to collect activations which can be used to fit an arbitrary non-linear representation. Furthermore, we introduce SurfaceRep, a method which controls concepts via a radial basis function network (RBFN) representation embedded in a low-dimensional space, to investigate whether a more complex, non-linear representation is able to form more accurate local approximations of concepts than linear representations. We evaluate SurfaceRep on several benchmarks for Artificial Intelligence (AI) safety and analyse the strengths and weaknesses of non-linear methods. We find that although the method does not consistently outperform linear methods, it remains useful as an interpretability tool for faithfully visualising representations of concepts.
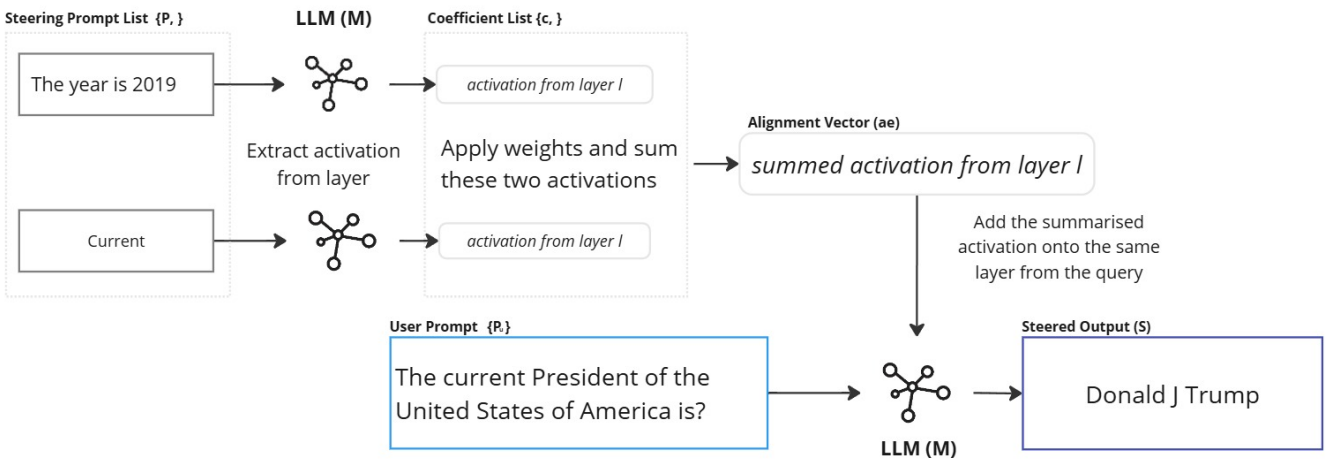
Temporal Alignment of Time Sensitive Facts with Activation Engineering | Link in here
Large Language Models (LLMs) are trained on diverse and often conflicting knowledge spanning multiple domains and time periods. Some of this knowledge is only valid within specific temporal contexts, such as answering the question, “Who is the President of the United States in 2022?” Ensuring LLMs generate time-appropriate responses is crucial for maintaining relevance and accuracy. In this work we explore activation engineering as a method for temporally aligning LLMs to improve factual recall without any training. Activation engineering has predominantly been used to steer subjective and qualitative outcomes such as toxicity or behavior. Our research is one of few that uncovers the bounds of activation engineering on objective outcomes. We explore an activation engineering technique to anchor LLaMA 2, LLaMA 3.1, Qwen 2 and Gemma 2 to specific points in time and examine the effects of varying injection layers and prompting strategies.